Portfolio Data Science
Project 1: Linear Regression, Students Performance
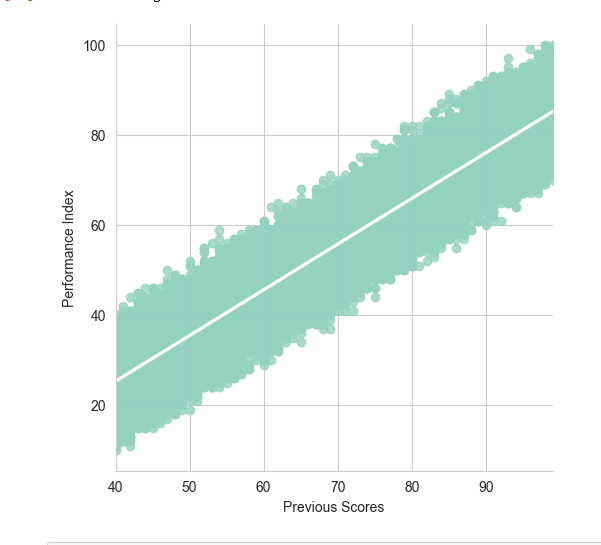
In this project, I applied regression and multi-regression analysis to an education database. The main goal was to predict what factors influence the student’s performance with higher probability. I used the sklearn.model package and seaborn for visualisation.
Here are the main steps of my work:
- Import in pandas the libraries and the file (.csv)
- Data exploration to find the first correlation
- Perform the ‘Test, Learn & Split’ test to train the model
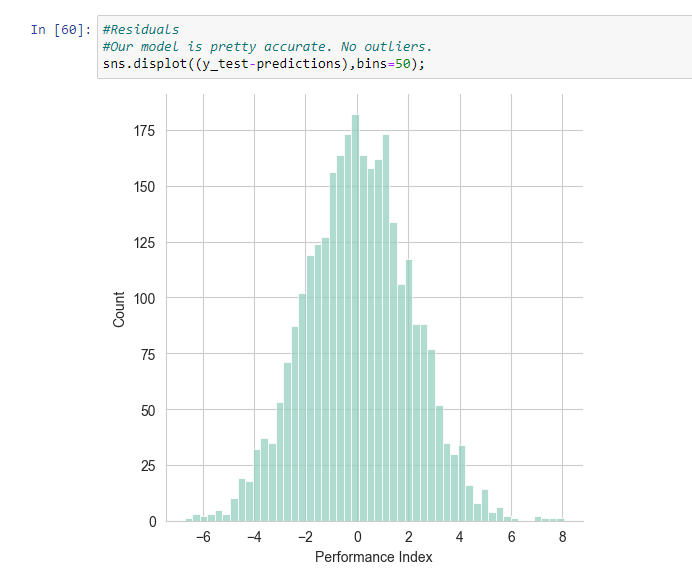
- Analyse the data to find outliers
- Final comments
Project 2: K-means Clustering to Find Highest Spending Audience
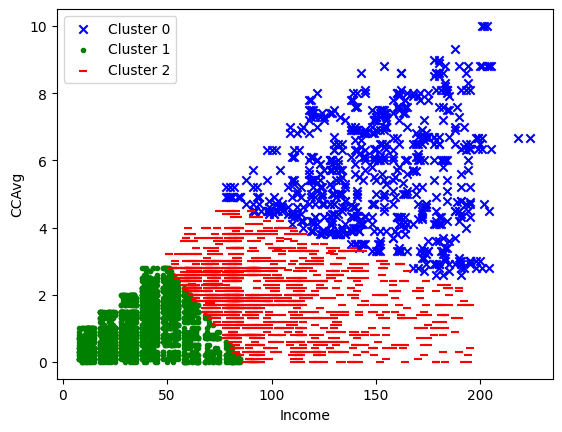
KMeans clustering is a powerful technique in marketing analytics to find new audiences based on similar users. It identifies customer segments through specific features. In this case, I’ve chosen 2 criteria: customer ‘Income’ and ‘Avg. Spending on Credit Card’ In the chart below we can see that we found 3 new audiences. Cluster 0 has a higher income and higher CCAvg. I would suggest the marketing team to address different marketing campaigns to this audience.
- I imported a new CSV file into pandas
- I imported KMeans library, Pandas, Numpy, Matplotlib for visualisation.
- I standardised two data columns by using the StandardScaler Method.
- I then applied the KMeans algorithm to find the natural clustering (N=3, random state 42) and I applied visualisation techniques.
Project Reference: Baig, Govindan, Shrimali, 2021, Data Science for Marketing Analytics: A practical guide to forming a killer marketing strategy through data analysis with Python, Packt.